10 Best LLM Tools to Run Models Locally (Top Picks for 2026)
1. Privacy Matters: Running LLMs locally ensures data remains secure and private.
2. Cost Savings: Eliminate cloud fees by using tools like Llama.cpp and GPT4All on your hardware.
3. Wide Compatibility: Tools like ONNX and Faraday.dev work across different hardware setups, making them versatile.
4. Ease of Use: Beginner-friendly options like LM Studio make local LLMs accessible to all.
5. Future-Ready: These tools are evolving, promising greater efficiency and applications across industries.
Imagine having the power of advanced AI right on your computer—no cloud, no delays, just complete control.
Running Large Language Models (LLMs) locally isn’t just about convenience; it’s about privacy, cost savings, and tailoring AI to fit your exact needs.
In this guide, we’ll explore the 10 best tools to run LLMs locally in 2026, perfect for anyone looking to stay ahead in the AI game.
Get ready to discover tools that bring AI closer to you than ever before!
ALSO READ: GPT-4o Mini vs Llama 3.1: Which AI Model is Best for Fine-Tuning?

What Are Large Language Models (LLMs)?
Large Language Models, or LLMs, are advanced AI systems trained on massive amounts of text data.
These models can understand and generate human-like text, making them incredibly useful for tasks like content creation, coding, language translation, and much more.
What makes LLMs special is their ability to process context and provide responses that feel natural.
Running these models locally means you don’t need to rely on the cloud, giving you greater control over your data and how the model performs.
Benefits of Running LLMs Locally
Running LLMs on your local machine might sound technical, but it comes with some major perks. Here’s why it’s worth considering:
1. Privacy and Security:
Your data stays with you, reducing the risk of leaks or breaches.
This is a huge plus if you’re working with sensitive information.
2. No Internet Dependency:
Since everything runs locally, you won’t have to rely on an internet connection to access the model.
3. Faster Response Times:
Local execution reduces latency, meaning the model processes and responds to tasks much faster.
4. Cost Savings:
You avoid ongoing fees for cloud-based services by using your hardware to run these tools.
5. Customizability:
Local models can be fine-tuned and adapted specifically to your needs, whether it’s tweaking the dataset or configuring parameters.
6. Reliability:
Without needing external servers, you’re less likely to experience downtime or interruptions.
Criteria for Selecting LLM Tools
Choosing the right tools to run LLMs locally can feel overwhelming, but focusing on key factors makes the decision much easier.
Here’s what to consider:
1. Hardware Compatibility:
Make sure the tool supports your system, whether it’s a high-end GPU or just a standard CPU. Some tools are more resource-intensive than others.
2. Ease of Use:
Look for tools with straightforward installation processes and user-friendly interfaces, especially if you’re new to running models locally.
3. Model Support:
Ensure the tool supports the type of LLM you plan to use, like GPT models or Llama-based architectures.
4. Community and Documentation:
A strong community and clear documentation can make troubleshooting and learning much easier.
5. Performance:
Check benchmarks to ensure the tool provides fast and efficient performance on your hardware.
6. Regular Updates:
Tools with active development and updates are more likely to stay compatible with the latest LLM advancements.
Top 10 LLM Tools to Run Models Locally in 2026
Here’s a closer look at the best tools for running Large Language Models (LLMs) locally.
Each of these tools has its strengths, so you can find the one that fits your needs perfectly.
1. Llama.cpp
An open-source tool designed to run Llama-based models efficiently on local hardware.
Why It’s Great:
It works on both GPUs and CPUs, meaning you don’t need expensive equipment to get started.
Its lightweight design ensures it’s resource-friendly while maintaining performance.
Best For:
Developers and hobbyists who want an accessible way to run models locally.
2. LM Studio
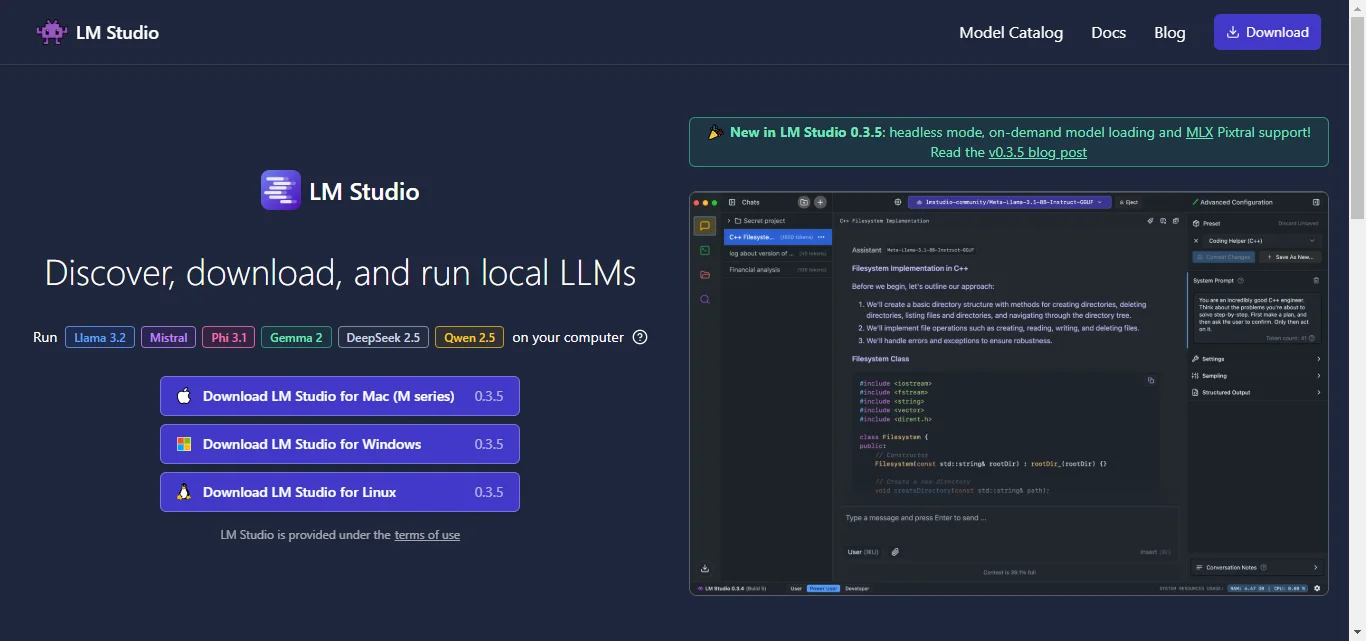
A GUI-based tool for running and fine-tuning language models on your machine.
Why It’s Great:
LM Studio simplifies the process with an intuitive interface, supporting multiple models.
It’s perfect for users who prefer a visual setup instead of complex code.
Best For:
Beginners or casual users who want a user-friendly tool without compromising on power.
3. Ollama
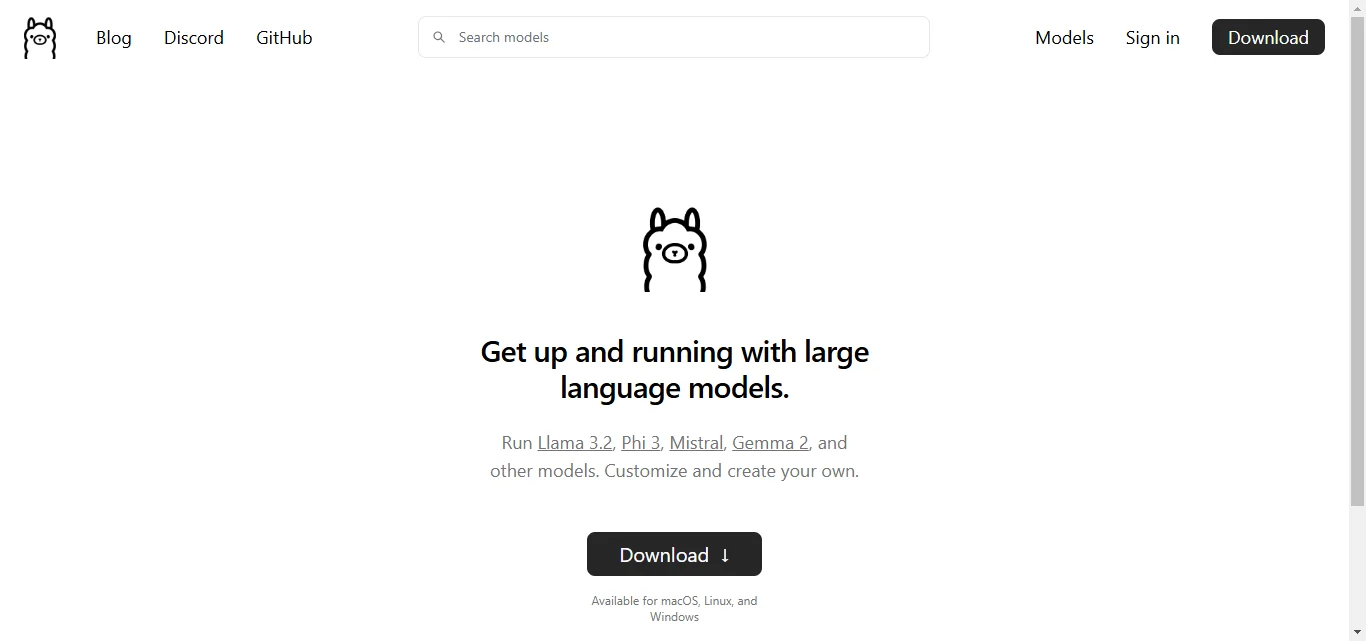
A platform offering pre-packaged LLMs ready to run locally with minimal setup.
Why It’s Great:
Ollama eliminates the hassle of configuration by providing out-of-the-box solutions.
It’s especially handy for teams that need quick deployment for specific projects.
Best For:
Teams or professionals looking for fast, ready-to-use local LLM solutions.
4. Faraday.dev
A versatile platform focused on local AI model training and deployment.
Why It’s Great:
Faraday.dev is a dream for developers who want to dive into advanced customizations.
It’s flexible, supports multiple architectures, and allows users to experiment with cutting-edge setups.
Best For:
Researchers and advanced users working on complex AI applications.
5. local.ai
A powerful tool for running various LLMs locally, offering broad compatibility and support.
Why It’s Great:
Local.ai excels in performance and usability, making it ideal for those who need a general-purpose platform with a strong community for support.
Best For:
Everyday users who need a reliable tool for multiple types of tasks.
6. OobaBogga Web UI
A web-based interface for running and interacting with local language models.
Why It’s Great:
OobaBogga allows users to access their models from any device with a browser, making it incredibly flexible for on-the-go experimentation and education.
Best For:
Educators, students, and experimenters looking for accessibility and convenience.
7. GPT4All
A dedicated tool for running GPT models locally without requiring heavy cloud infrastructure.
Why It’s Great:
GPT4All provides pre-trained GPT models that run efficiently on standard hardware, even CPUs, making it a go-to choice for those avoiding cloud fees.
Best For:
Users who need GPT capabilities on budget-friendly setups.
8. ONNX (Open Neural Network Exchange)
A framework for optimizing and running AI models across various hardware environments.
Why It’s Great:
ONNX supports model optimization, making it a great choice for those aiming to maximize performance while minimizing resource usage.
Best For:
Professionals working on production-level AI solutions.
9. LlamaIndex
A specialized tool that works with LLMs for indexing and retrieving large datasets.
Why It’s Great:
LlamaIndex enhances LLM performance in data-driven scenarios by seamlessly integrating data indexing and retrieval processes.
Best For:
Data scientists and researchers dealing with large-scale knowledge management.
10. Runpod
A scalable solution for deploying local models in isolated, containerized environments.
Why It’s Great:
Runpod combines the benefits of local control with scalability, making it a robust choice for businesses managing large workloads.
Best For:
Enterprise users who need flexibility and scalability in their LLM deployment.
Comparison of the Top 10 LLM Tools
Now that we’ve explored the best tools for running LLMs locally, let’s compare them based on key factors to help you choose the right one.
1. Hardware Compatibility
Llama.cpp: Works on both GPUs and CPUs, great for resource-limited setups.
ONNX: Optimized for multiple hardware types, including advanced GPUs.
GPT4All: Efficient on standard CPUs, perfect for budget-friendly systems.
2. Ease of Use
LM Studio: User-friendly GUI with minimal setup required.
Ollama: Pre-packaged models simplify deployment for beginners.
OobaBogga: Web-based interface makes it accessible from any browser.
3. Supported Models
Faraday.dev: Offers broad support for custom and experimental architectures.
LlamaIndex: Specializes in Llama-based models with advanced data integration.
Runpod: Supports containerized deployments for flexibility.
4. Performance
ONNX: High efficiency with optimized execution across platforms.
local.ai: Reliable performance for various tasks without major resource demands.
5. Best Use Cases
LlamaIndex: Ideal for data-intensive tasks like indexing and retrieval.
Slack Integration with Make.com: Perfect for customer support automation (real-life use case).
Runpod: Scalable for enterprise-level solutions.
6. Community and Support
GPT4All: Backed by an active user community with plenty of resources.
Faraday.dev: Frequent updates and strong developer support.
Installation and Setup Guide
Getting started with these LLM tools might seem technical, but most of them offer straightforward installation processes.
Here’s a general step-by-step guide to help you set up and run your preferred LLM tool locally:
1. Choose the Right Tool
Identify which tool from the list matches your hardware, use case, and expertise.
For instance, beginners might prefer LM Studio, while advanced users may go for Faraday.dev.
2. Check System Requirements
Visit the official website of the selected tool to verify the system requirements.
Ensure your hardware, like CPU, GPU, and RAM, meets the recommended specifications.
3. Download and Install the Tool
Navigate to the tool’s official website or GitHub repository.
Download the installation package compatible with your operating system (Windows, macOS, or Linux).
Follow the installation steps provided in the documentation or installer wizard.
4. Set Up Dependencies
Some tools, like Llama.cpp or ONNX, require additional software dependencies, such as Python, CUDA, or specific libraries.
Use the provided commands or package managers (e.g., pip, npm) to install dependencies.
5. Load or Train Your Model
If you’re running pre-trained models:
Download the model weights or files from the tool’s repository or community links.
Place them in the specified directory according to the documentation.
If you’re training a model:
Use the tool’s setup guide to prepare your training dataset and configure training parameters.
6. Run a Test
Launch the tool and test it with sample prompts or data.
For instance, in GPT4All, you can input a sample query to see how the model responds locally.
7. Fine-Tune and Customize
Depending on your requirements, adjust parameters, integrate APIs, or connect additional tools to optimize the performance of your LLM.
8. Seek Community Support
Join forums, communities, or Discord groups for your selected tool to troubleshoot issues or learn tips from other users.
Challenges and Considerations
While running LLMs locally comes with plenty of benefits, there are some challenges and considerations to keep in mind:
1. Hardware Limitations
Running LLMs locally requires significant computational power, especially for large models.
If your hardware lacks sufficient GPU or RAM, the performance may be slower or suboptimal.
2. Complex Setup
Some tools, like Faraday.dev or ONNX, might require advanced technical knowledge for setup and fine-tuning.
Beginners might face a learning curve, especially when dealing with dependencies or configurations.
3. Storage Requirements
Large models often require substantial storage space for model weights and additional files.
Ensure your system has enough storage capacity to handle these requirements.
4. Maintenance and Updates
Running models locally means you’re responsible for keeping the software updated and troubleshooting issues.
Unlike cloud solutions, there’s no automatic maintenance or centralized support.
5. Limited Collaboration
Local setups are great for individual use but might pose challenges for team collaboration compared to cloud-based tools.
Sharing models or workflows requires additional steps, such as using shared drives or external tools.
6. Energy Consumption
Running powerful models on local machines, especially GPUs, can lead to increased energy consumption, which may not be ideal for all users.
Tips to Overcome Challenges:
Optimize Models:
Use tools like ONNX to reduce model size and improve efficiency.
Start Small:
Begin with lightweight tools like Llama.cpp to gain experience before moving to more complex solutions.
Seek Community Support:
Leverage forums and user communities to solve issues and learn best practices.
Conclusion: 10 Best LLM Tools To Run Models Locally (Top Picks for 2026)
Running Large Language Models (LLMs) locally is no longer just a technical novelty—it’s a practical solution for privacy, efficiency, and cost savings.
Tools like Llama.cpp, GPT4All, and ONNX make it possible for anyone, from developers to businesses.
While challenges like hardware limitations and setup complexity exist, the benefits often outweigh the hurdles.
As technology evolves, local LLM tools are only getting more accessible and powerful, making them a valuable asset for innovation and productivity in 2026 and beyond.
Keep going: the prompt library has AI coding prompts and Claude prompts ready to copy and run.