GPT-4o Mini vs Llama 3.1: Which AI Model is Best for Fine-Tuning?
1. GPT-4o Mini is cost-effective and ideal for general-purpose fine-tuning with lower computational demands.
2. Llama 3.1 offers unmatched customization and scalability but requires advanced resources and expertise.
3. Fine-tuning enhances AI performance by tailoring it to specific tasks or industries.
4. Llama 3.1’s open-source flexibility makes it suitable for research and complex applications.
5. GPT-4o Mini’s ease of use is perfect for businesses seeking accessible AI solutions.
When it comes to fine-tuning AI models, GPT-4o Mini and Llama 3.1 are two big names that often come up.
But which one is actually the best for fine-tuning?
If you’ve ever wondered how to take a pre-trained AI model and adapt it to your specific needs, this guide is for you.
ALSO READ: 15 Mind-blowing ChatGPT Features

What is Fine-Tuning?
Fine-tuning is a process used to customize an existing AI model so it can perform specific tasks better.
Think of it like taking a general-purpose AI and teaching it specialized skills based on what you need.
Here’s how it works in simple terms:
1. Start with a Pre-Trained Model:
You begin with an AI model, like GPT-4o Mini or Llama 3.1, which has already been trained on a large amount of general data, like books, articles, and websites.
2. Feed It Task-Specific Data:
To fine-tune it, you provide the AI with data focused on a specific task.
For example, if you want the AI to summarize legal documents, you would give it samples of legal text and summaries.
3. Adjust Its Knowledge:
The AI uses this new data to update and refine how it generates answers or completes tasks, becoming more accurate and reliable for the job.
Why Fine-Tuning is Important
Better Accuracy:
Fine-tuned models are better at solving specific problems because they’re trained with relevant examples.
Custom Responses:
Instead of generic answers, the AI learns to provide solutions tailored to your needs, whether for healthcare, e-commerce, or customer service.
Saves Time and Resources:
Rather than building an AI from scratch, fine-tuning allows you to adapt a pre-trained model quickly.
Real-Life Example
Imagine you run a travel company.
By fine-tuning an AI model with travel-related data, like itineraries and FAQs, it could answer customer queries in a detailed, industry-specific way, rather than giving vague, general responses.
Fine-tuning helps turn a powerful, pre-trained model into an AI assistant designed just for you.
GPT-4o Mini: Overview and Features

GPT-4o Mini is a compact version of OpenAI’s GPT-4o model, designed to be more affordable and efficient.
Released in July 2024, it aims to make advanced AI accessible to a broader audience.
Key Features:
1. Cost-Effective:
Priced at 15 cents per million input tokens and 60 cents per million output tokens.
GPT-4o Mini is over 60% cheaper than GPT-3.5 Turbo, making it a budget-friendly option for businesses and developers.
2. Performance:
Despite its smaller size, GPT-4o Mini scores 82% on the Massive Multitask Language Understanding (MMLU) benchmark, outperforming some larger models in chat preferences.
3. Multimodal Capabilities:
Initially supporting text and vision inputs, GPT-4o Mini is expected to expand to include text, image, video, and audio inputs and outputs, enhancing its versatility.
4. Accessibility:
Available to ChatGPT Free, Plus, and Team users, as well as enterprise clients, GPT-4o Mini offers a wide range of users access to advanced AI functionalities.
5. Fine-Tuning Potential:
GPT-4o Mini’s design allows for efficient fine-tuning, enabling users to adapt the model to specific tasks or industries.
Its cost-effectiveness and performance make it a practical choice for businesses looking to implement AI solutions without significant financial investment.
Llama 3.1: Overview and Features
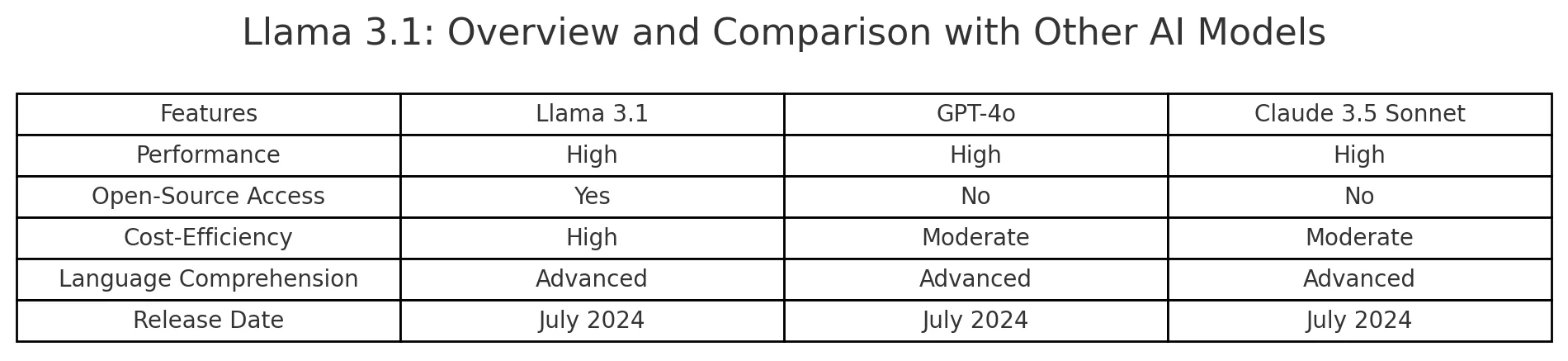
Llama 3.1, developed by Meta, is an advanced open-source AI model designed to rival leading proprietary models like GPT-4o and Claude 3.5 Sonnet.
Released in July 2024, it offers significant enhancements over its predecessors.
Key Features:
1. Parameter Scale:
Llama 3.1 is available in three sizes: 8 billion, 70 billion, and 405 billion parameters, with the 405B model being the largest open-source AI model to date.
2. Extended Context Length:
The model supports a context length of up to 128,000 tokens, allowing it to handle extensive inputs effectively.
3. Multilingual Support:
Llama 3.1 includes support for eight additional languages, including French, German, Hindi, Italian, Portuguese, and Spanish.
Hereby enhancing its usability across diverse linguistic contexts.
4. Open-Source Accessibility:
As an open-source model, Llama 3.1 provides developers and researchers with the flexibility to customize and fine-tune the model for specific applications.
5. Fine-Tuning Potential:
Llama 3.1’s open-source nature and extensive parameter options make it a versatile choice for fine-tuning across various tasks and industries.
Its large context window and multilingual capabilities further enhance its adaptability for specialized applications.
Fine-Tuning Capabilities of GPT-4o Mini and Llama 3.1
Fine-tuning is the process of adapting a pre-trained AI model to perform specific tasks more effectively by training it further on domain-specific data.
Let’s look at how GPT-4o Mini and Llama 3.1 handle fine-tuning.
GPT-4o Mini:
Fine-Tuning Support:
OpenAI offers fine-tuning for GPT-4o Mini, allowing developers to customize the model for their applications.
This feature is available to all developers on paid usage tiers.
Cost and Resources:
Fine-tuning GPT-4o Mini is cost-effective, with training priced at $25 per million tokens and inference at $3.75 per million input tokens and $15 per million output tokens.
The model’s smaller size compared to its larger counterparts means it requires less computational power, making it accessible for businesses with limited resources.
Customization Flexibility:
Developers can adjust the model’s style, tone, and format to align with specific use cases, improving reliability and accuracy.
Fine-tuning is particularly beneficial for handling complex prompts or performing new tasks that prompt engineering alone cannot achieve.
Llama 3.1:
Fine-Tuning Support:
Llama 3.1, being open-source, provides extensive flexibility for fine-tuning.
Developers can access the model’s weights and adapt it to various tasks, benefiting from the open-source community’s contributions.
Cost and Resources:
While Llama 3.1 is freely available, fine-tuning, especially for larger models like the 405B parameter version, requires significant computational resources.
Fine-tuning Llama 3.1 405B on a single node is challenging due to its size, necessitating optimized implementations and advanced hardware.
Customization Flexibility:
The open-source nature of Llama 3.1 allows for deep customization.
Developers can modify the model extensively to suit specific needs, making it suitable for a wide range of applications.
Comparison:
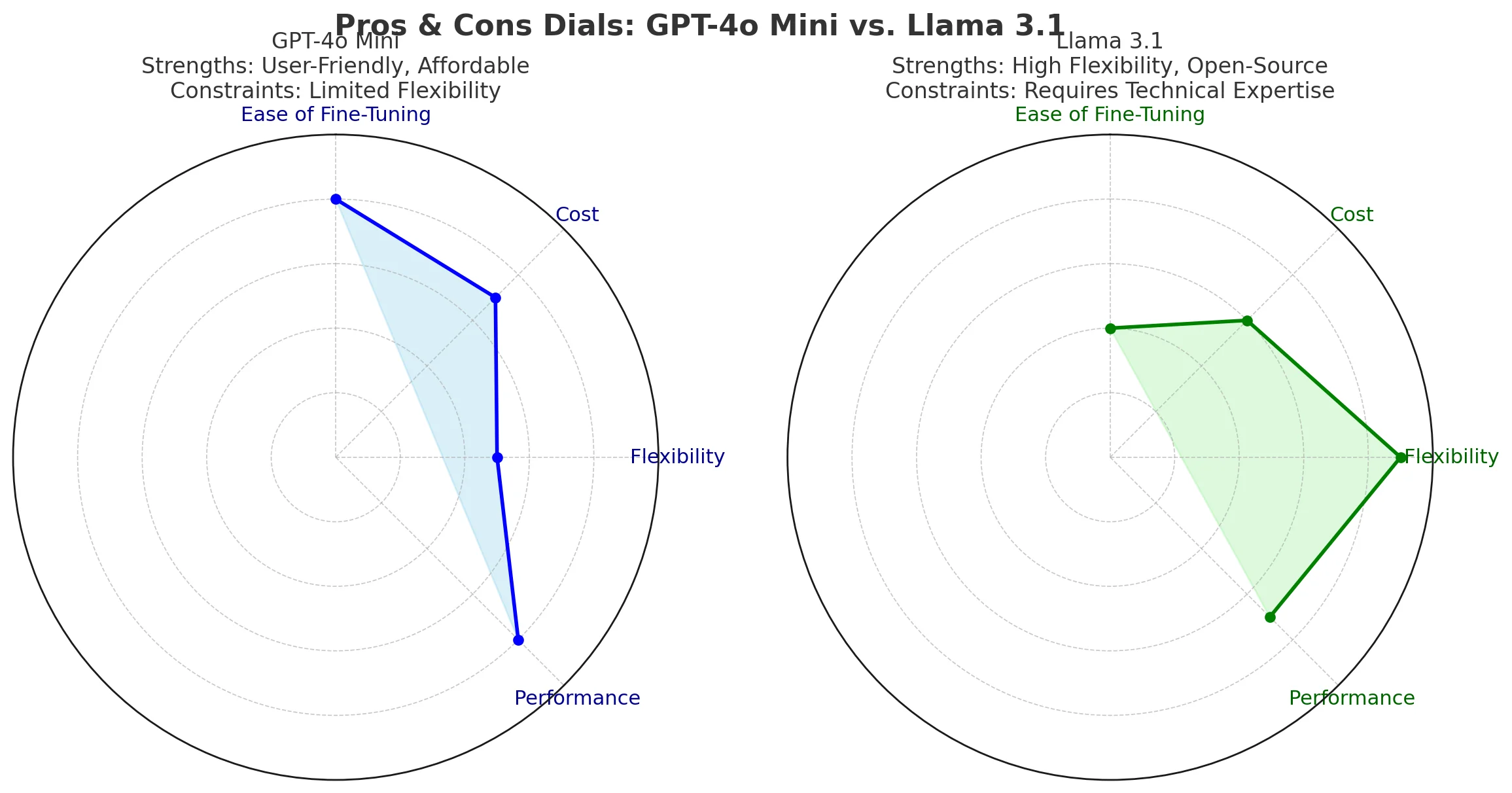
Ease of Fine-Tuning:
GPT-4o Mini offers a more straightforward fine-tuning process through OpenAI’s platform, making it user-friendly for developers without extensive AI expertise.
In contrast, fine-tuning Llama 3.1 may require more technical knowledge and resources, especially for larger models.
Cost Considerations:
GPT-4o Mini’s fine-tuning involves specific costs, but its efficiency may offset expenses for certain applications.
Llama 3.1, being open-source, has no licensing fees, but the computational costs for fine-tuning large models can be substantial.
Flexibility and Control:
Llama 3.1 provides greater flexibility due to its open-source nature, allowing for extensive modifications.
GPT-4o Mini, while customizable, operates within the constraints of OpenAI’s platform.
That’s to say GPT-4o Mini is suitable for developers seeking an accessible and cost-effective fine-tuning process with moderate customization needs.
Llama 3.1 is ideal for those requiring deep customization and who have the resources to manage its computational demands.
Performance and Evaluation
When choosing between GPT-4o Mini and Llama 3.1 for fine-tuning, it’s important to consider their performance across various tasks and benchmarks.
Benchmark Performance Metrics:
GPT-4o Mini:
Achieves an MMLU (Massive Multitask Language Understanding) score of 82.0, indicating strong general performance across diverse tasks.
Llama 3.1:
The 70B parameter model scores 83.6 on the MMLU benchmark, slightly outperforming GPT-4o Mini.
Real-World Applications:
GPT-4o Mini:
Excels in general-purpose tasks, including text generation, summarization, and translation.
Its compact architecture makes it suitable for applications requiring efficiency and speed.
Llama 3.1:
Demonstrates strong capabilities in technical and scientific domains, benefiting from its extensive training data.
Its larger model size allows for nuanced understanding and generation, making it ideal for complex tasks.
User Case Studies:
GPT-4o Mini:
Businesses have utilized GPT-4o Mini for customer service automation, content creation, and data analysis, appreciating its balance between performance and resource requirements.
Llama 3.1:
Research institutions have adopted Llama 3.1 for specialized tasks in natural language processing and machine learning research, leveraging its open-source nature for customization.
Summary:
Both models offer robust performance, with Llama 3.1 holding a slight edge in benchmark scores.
However, GPT-4o Mini’s efficiency and cost-effectiveness make it a compelling choice for a wide range of applications.
Cost and Resource Analysis
When choosing between GPT-4o Mini and Llama 3.1 for fine-tuning, it’s essential to consider both financial and computational resources.
GPT-4o Mini:
Licensing and Access Costs:
OpenAI offers GPT-4o Mini with a pricing structure of $3.00 per million input tokens and $12.00 per million output tokens.
Computational Resources:
Due to its smaller size, GPT-4o Mini requires less computational power, making it accessible for businesses with limited hardware capabilities.
Long-Term Maintenance Costs:
Utilizing OpenAI’s infrastructure reduces the need for extensive maintenance, as updates and optimizations are managed by OpenAI.
Llama 3.1:
Licensing and Access Costs:
As an open-source model, Llama 3.1 is freely available, eliminating licensing fees.
Computational Resources:
Fine-tuning larger versions, such as the 405B parameter model, demands significant computational resources, including high-end GPUs and substantial memory.
Long-Term Maintenance Costs:
Managing and updating the model requires dedicated technical expertise and resources, as maintenance is the user’s responsibility.
Comparison:
Initial Investment:
GPT-4o Mini involves predictable costs through OpenAI’s pricing, while Llama 3.1 offers a cost advantage by being free to access.
Operational Expenses:
Llama 3.1 may incur higher operational costs due to its computational demands, especially for larger models.
Scalability:
GPT-4o Mini provides scalable solutions with manageable costs, whereas scaling Llama 3.1 requires careful planning of computational resources.
In summary, GPT-4o Mini offers a cost-effective and resource-efficient option for fine-tuning, suitable for businesses seeking manageable expenses.
Llama 3.1 provides flexibility and control but necessitates significant computational resources and technical expertise.
Community and Support
When selecting an AI model for fine-tuning, the availability of community resources and support is crucial.
Let’s examine what GPT-4o Mini and Llama 3.1 offer in this regard.
GPT-4o Mini:
Documentation and Tutorials:
OpenAI provides comprehensive guides and tutorials to assist users in fine-tuning GPT-4o Mini.
These resources cover setup, best practices, and troubleshooting, making the process more accessible.
Developer and User Communities:
An active community exists around OpenAI’s models, including forums and discussion groups where users share experiences, solutions, and insights.
This collaborative environment fosters learning and problem-solving.
Official Support and Updates:
OpenAI offers customer support for GPT-4o Mini users, addressing technical issues and inquiries.
Regular updates and improvements are rolled out, ensuring the model remains current and effective.
Llama 3.1:
Documentation and Tutorials:
Meta provides detailed documentation for Llama 3.1, including model cards and responsible use guides.
These resources help users understand the model’s capabilities and ethical considerations.
Developer and User Communities:
As an open-source model, Llama 3.1 benefits from a vibrant community of developers and researchers.
Platforms like GitHub host repositories where users collaborate, share code, and contribute to the model’s development.
Official Support and Updates:
While Meta provides the initial release and documentation, ongoing support and updates are largely community-driven.
Users rely on the collective efforts of the community for enhancements and troubleshooting.
Comparison:
Accessibility of Resources:
Both models offer extensive documentation, but GPT-4o Mini’s resources are more centralized through OpenAI, whereas Llama 3.1’s are distributed across community platforms.
Community Engagement:
Llama 3.1’s open-source nature fosters a more collaborative and dynamic community, encouraging user contributions and shared advancements.
Support Structure:
GPT-4o Mini provides official support channels, offering direct assistance from OpenAI.
In contrast, Llama 3.1 relies on community support, which can vary in responsiveness and expertise.
In summary, GPT-4o Mini offers structured support with official channels and regular updates, suitable for users seeking a more managed experience.
Llama 3.1 provides a collaborative environment with community-driven support, ideal for those who prefer open-source flexibility and active engagement.
Pros and Cons
Let’s break down the advantages and disadvantages of GPT-4o Mini and Llama 3.1 to help you make an informed decision.
GPT-4o Mini Pros:
Cost-Effective:
Offers competitive pricing, making it accessible for businesses with limited budgets.
Efficient Fine-Tuning:
Requires less computational power, reducing infrastructure costs.
User-Friendly:
Supported by OpenAI’s platform, making fine-tuning straightforward for developers with minimal AI expertise.
Comprehensive Support:
Backed by official documentation, tutorials, and direct customer support.
Performance:
Consistently performs well across general-purpose tasks, with strong benchmark scores.
Cons:
Limited Customization:
Operates within the constraints of OpenAI’s platform, reducing flexibility for deep modifications.
Smaller Community:
While it has an active community, it’s not as expansive or collaborative as open-source ecosystems.
Restricted Use Cases:
Focused more on general applications, which may not fully address niche requirements.
Llama 3.1 Pros:
Open-Source Flexibility:
Offers complete control and customization, ideal for researchers and advanced developers.
Large Parameter Models:
Provides scalability with options up to 405 billion parameters, suitable for complex tasks.
Vibrant Community:
Supported by an active and collaborative open-source community, fostering innovation.
No Licensing Costs:
Free to access, eliminating upfront costs for the model itself.
Advanced Features:
Multilingual support and extended context lengths make it versatile for diverse applications.
Cons:
High Computational Demands:
Larger models require significant hardware and infrastructure, increasing costs for fine-tuning and deployment.
Steep Learning Curve:
Fine-tuning and customization demand advanced technical knowledge and expertise.
Community-Driven Support:
Relies on community contributions for updates and troubleshooting, which can vary in quality and responsiveness.
Maintenance Responsibility:
Users are responsible for managing and updating the model, requiring ongoing technical investment.
Comparison Summary:
Ease of Use:
GPT-4o Mini is simpler to fine-tune and deploy, making it suitable for businesses and developers without deep AI expertise.
Flexibility:
Llama 3.1’s open-source nature offers unmatched customization and scalability, ideal for research and highly specialized applications.
Cost Efficiency:
GPT-4o Mini balances cost and performance well, while Llama 3.1’s computational expenses can outweigh its free licensing for some users.
Support:
GPT-4o Mini’s official support channels provide a more structured experience, whereas Llama 3.1 benefits from a decentralized, community-driven approach.
Wrapping Up: GPT-4o Mini vs Llama 3.1: Which AI Model is Best for Fine-Tuning?
Choosing between GPT-4o Mini and Llama 3.1 depends on your needs.
GPT-4o Mini is cost-effective and user-friendly, making it ideal for businesses seeking efficient fine-tuning with minimal resources.
Llama 3.1, as an open-source model, offers unmatched customization and scalability but requires significant technical expertise and computational power.
For general applications, GPT-4o Mini excels, while Llama 3.1 is perfect for advanced, specialized use cases.
Select based on your goals and resources.